[摘要] 使用Hadoop数据库”SQL-on-Hadoop”技术,可使得我们可以使用熟悉的 sql-engine 来访问存储在 hadoop 中的大数据。通过合理的查询优化等交给 hadoop 分布式计算处理,最后通过各种报表或分析工具来处理和研究数据。
在SQL-on-Hadoop之前,仅限于有少数几个接口可以访问到大数据(HDFS)的内容,这样我们必须对Hadoop框架有非常深入的了解,比如熟悉Hadoop分布式文件系统(HDFS),会写MapReduce或操作HBase来处理和分析数据。
现在,由于SQL-on-Hadoop,每个人都可以使用其最喜欢的工具,大数据使用的门槛更低,将有更多的人可以对大数据进行方便的操作,促使大数据的利用率和投资回报大大提高。
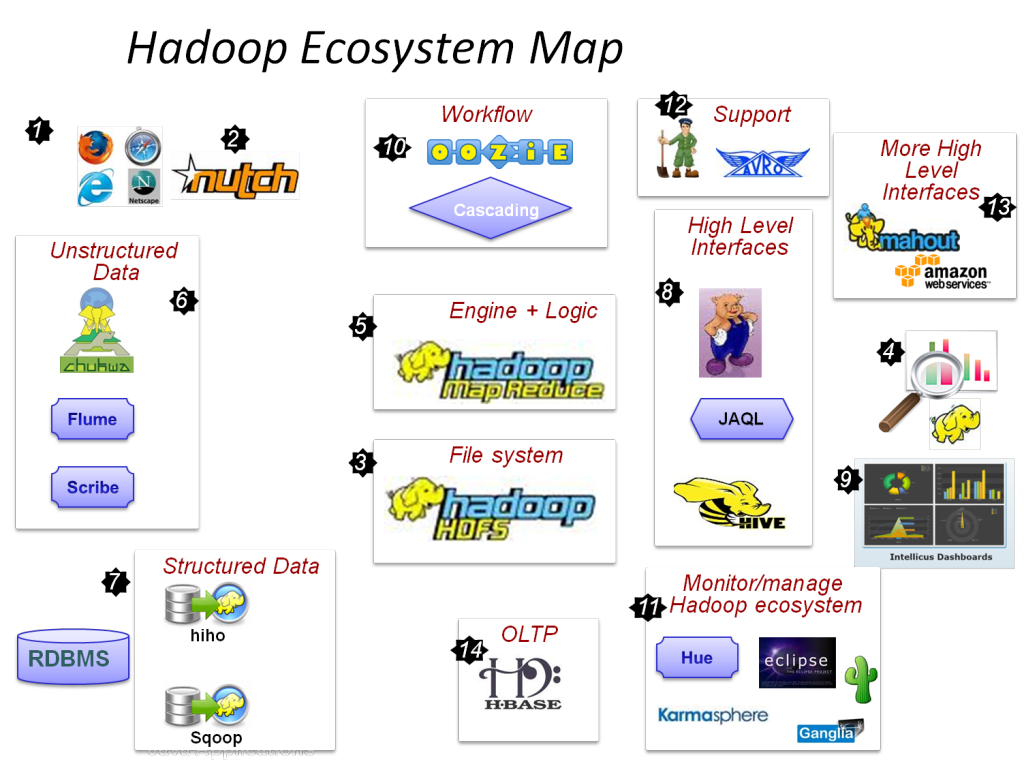
我们知道第一个Hadoop数据库引擎是Apache的Hive,但在过去的几个月中,已经不断涌现出了众多的适用于Hadoop的数据库引擎。比如:CitusDB,Cloudera Impala,Concurrent Lingual,Hadapt,InfiniDB,JethroData,MammothDB,Apache Drill,MemSQL,Pivotal HawQ,Progress DataDirect,ScleraDB,Simba和Splice Machine。
除了这些已经发布出来的数据库产品,所有数据虚拟化服务也应该被包括进来,因为它们也提供着对Hadoop数据的SQL访问。实际上,大数据Hadoop被设计为可以使用各种数据源,例如:数据虚拟化服务–Cirro 数据中心,Cisco 信息服务,Denodo 平台,Informatica 数据服务,红帽JBoss数据虚拟化和Stone Bond企业启动器,Virtuoso等等。
当然,还有一些SQL数据库管理系统支持多语言的持久性。这意味着他们可以在本地数据库或者在Hadoop中存储数据;
也可以提供通过SQL来访问Hadoop数据。例如:EMC / Greenplum UAP,HP Vertica(在MapR上),
Microsoft PolyBase,Actian ParAccel和Teradata Aster数据库(通过SQL-H)。
那么面对众多SQL引擎该如何选择呢?
虽然这些sql引擎在外面都看起来一样,都是通过类SQL方式来获取hadoop数据,但他们内部实现都是不同的。
例如,CitusDB能够知道所有数据存储的位置,并提供有效地访问数据的方式。JethroData通过存储索引来获得对数据的直接访问;Splice Machine则提供了一个事务性的SQL接口。
选择正确的SQL-on-Hadoop技术与sql引擎时需要详细的调研与测试,在选择一个可用的SQL引擎之前要进行评估,主要包括如下三点:
(1)SQL语言的丰富程度。
SQL语言支持的越丰富,可以从中受益的应用程序的范围越广,另外SQL语言越丰富,可通过查询处理的数据越复杂,则需要通过应用程序和统计报表工具进行二次计算的就越少。
(2)数据关联查询。
在数据量巨大的表上快速有效地执行关联查询并不容易,特别是如果SQL-on-Hadoop引擎不知道数据存储在何处。
关联查询时可能产生大量的I/O操作,导致导致Hadoop节点之间产生巨大的数据传输,这将导致性能急剧下降。
(3)Hadoop存储的为非传统数据。
最初,SQL是被设计为处理高度结构化的数据:表中的每个记录具有相同的列集合,每个列都保存一个原子值等等。
但是并不是所有在Hadoop中保存的大数据都有这样高度结构化的数据集合。 Hadoop文件中可以包含嵌套数据,可变数据(具有层次结构),无模式数据以及自描述数据等等。SQL-on-Hadoop引擎必须能够将所有这些形式的数据转换为平面关系型数据,并且还必须能够对这些形式的数据查询进行优化。
